Watermarking is now used to authenticate LLM outputs. But we know surprisingly little about how it affects model behavior. In our new paper, “Watermarking Degrades Alignment in Language Models: Analysis and Mitigation,” presented at the 1st GenAI Watermarking Workshop at ICLR 2025, we investigate how watermarking impacts key alignment properties such as truthfulness, safety, and helpfulness.
Watermarking methods try to perturb token selection as little as possible. But even small distributional shifts degrade alignment — and perplexity does not catch this.
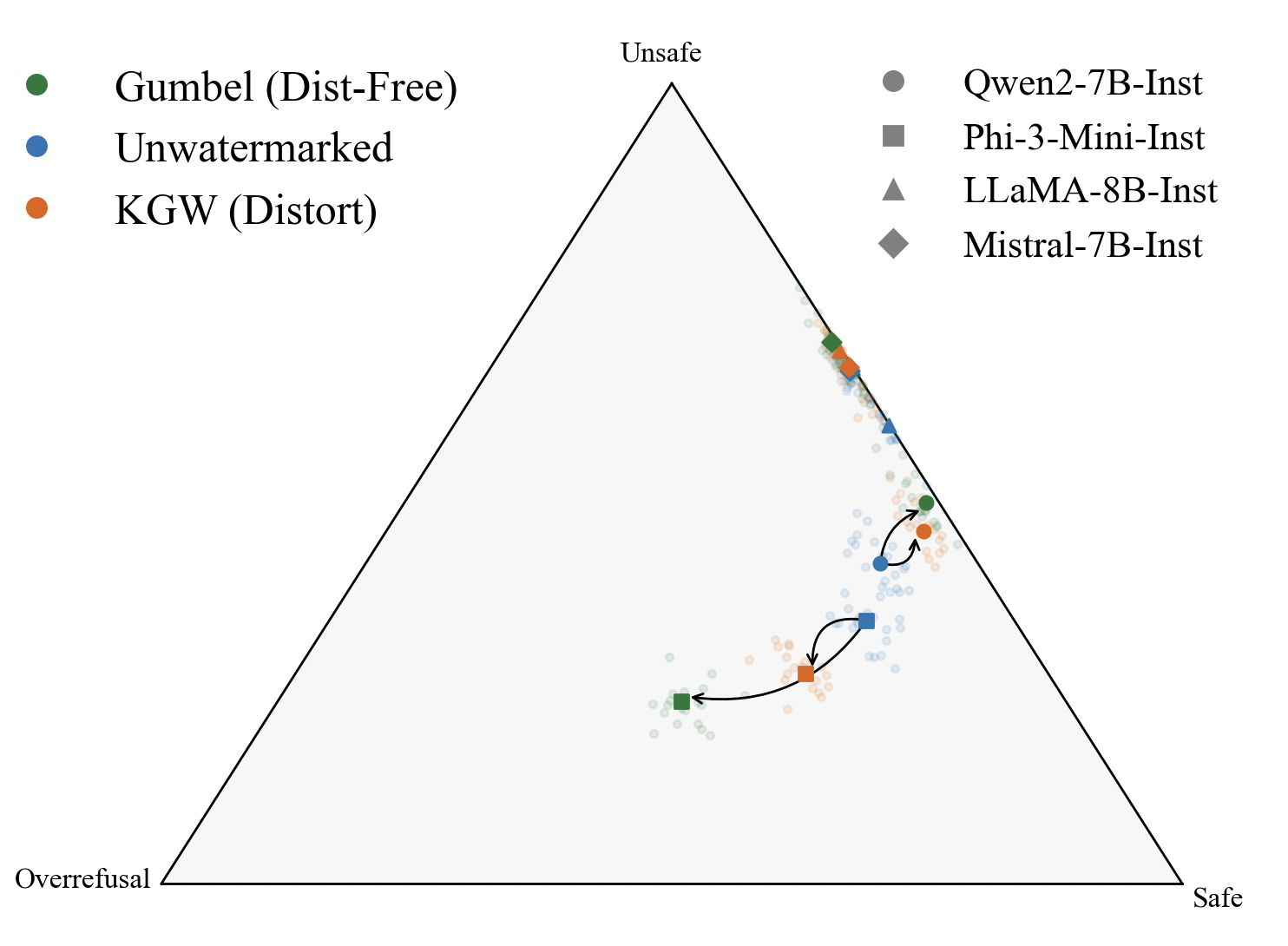
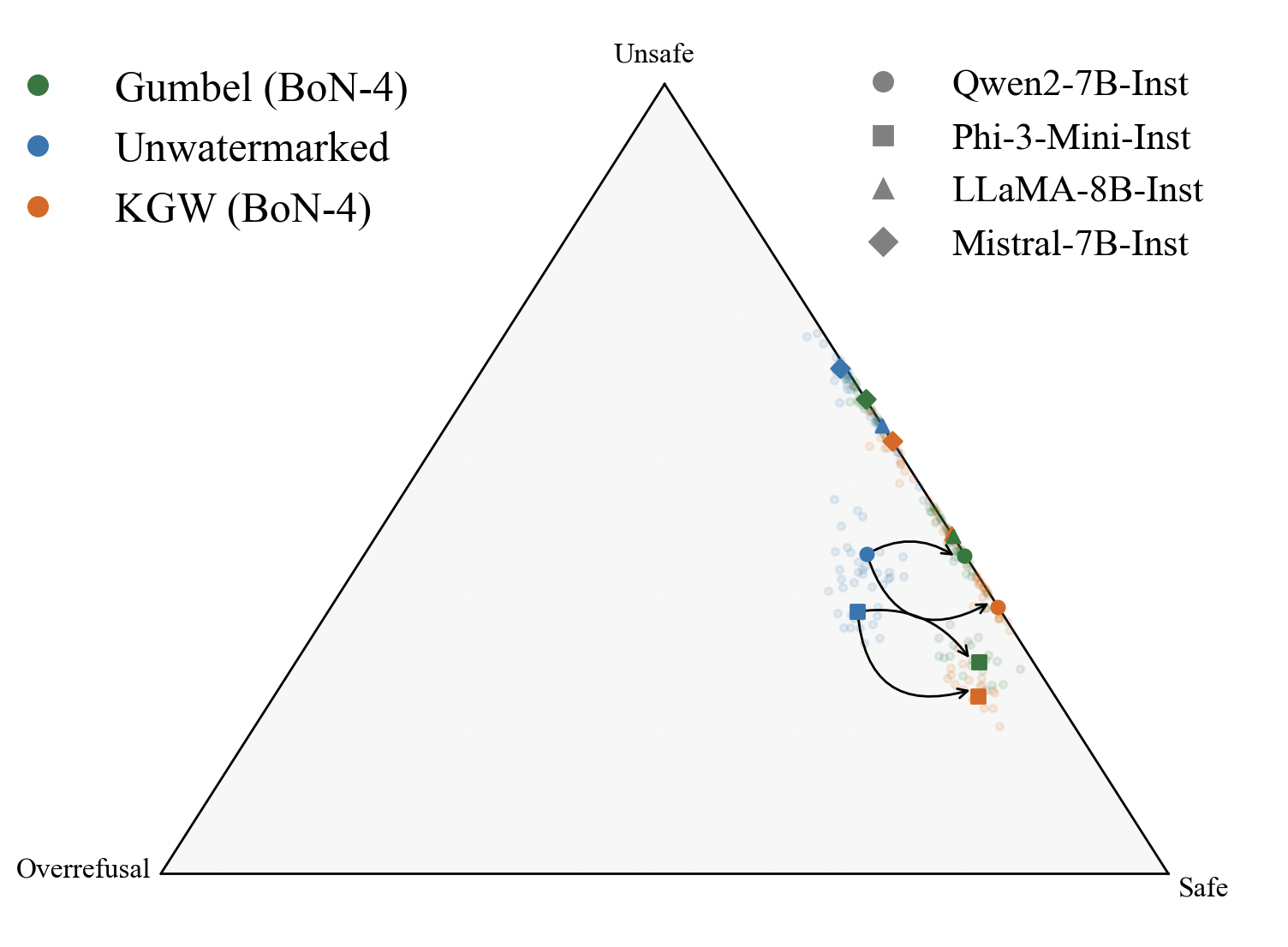
Figure 1: Simplex denoting the safety profiles of LLMs with watermarking. KGW and Gumbel Watermarking schemes tend to increase unsafe responses or overrefusal behaviors (Left) while Alignment Resampling effectively recovers or surpasses baseline (unwatermarked) alignment scores (Right).
Curse of Watermarking
Watermarking causes two behavioral shifts: guard amplification and guard attenuation. In guard amplification, models become overly cautious, increasing refusal rates even for benign queries. In guard attenuation, increased helpfulness weakens the safety profile, making models more likely to produce unsafe outputs.
There’s a fundamental trade-off: stronger watermarks hurt alignment. We call this the Watermarking Dilemma.
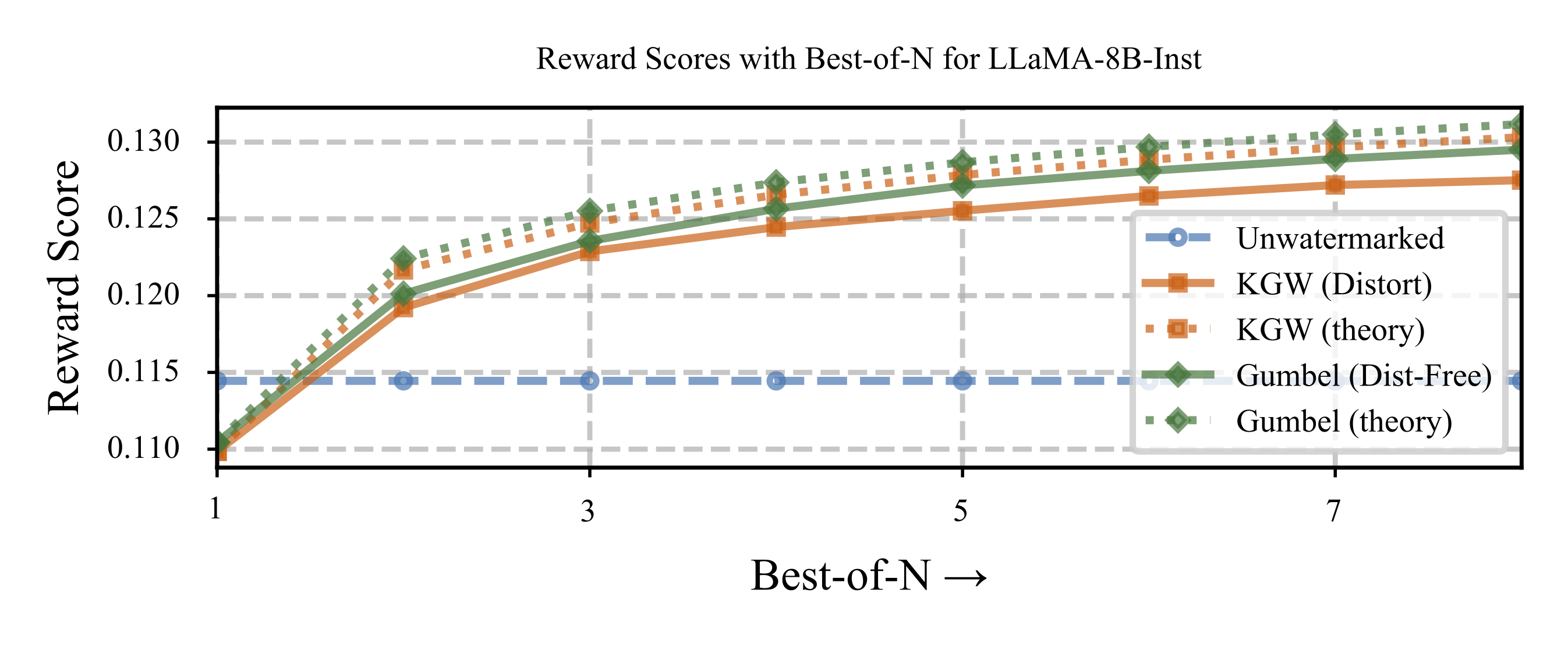
Our fix is simple. Sample multiple watermarked generations and pick the best one using a reward model. We call this Alignment Resampling. The theory works out nicely. Alignment recovery improves sub-logarithmically with the number of samples:
$$ \mathbb{E}[r_{\text{best of }n}] - \mathbb{E}[r_{\text{unwatermarked}}] \geq C \sqrt{\log n} - \varepsilon $$
where $\varepsilon$ captures the initial alignment degradation caused by watermarking and $n$ is the number of generations.
Modified Gumbel Watermarking
Here’s the default Gumbel watermark.
# Original Gumbel Watermark (Distortion Free)
seed = hash(preceding_tokens) # Hash previous tokens
rng.manual_seed(seed) # Set deterministic seed
rs = torch.rand(vocab_size, generator=rng) # Gumbel noise
scores = torch.pow(rs, 1/probs) # Compute Scores
next_token = torch.argmax(scores) # Deterministic
Our modification replaces argmax with multinomial sampling.
# Modified Gumbel Watermark
seed = hash(preceding_tokens) # Hash previous tokens
rng.manual_seed(seed) # Set deterministic seed
rs = torch.rand(vocab_size, generator=rng) # Gumbel noise
scores = torch.pow(rs, 1/probs) # Compute Scores
next_token = torch.multinomial(scores) #Stochastic
This preserves the relative ordering from the Gumbel-max trick, but adds randomness through multinomial sampling. The cost? It violates the distortion-free property. The benefit? We can now generate diverse samples.
Alignment Resampling (AR)
KGW is compatible with Alignment Resampling (AR) by default. With the modification above, we also make Gumbel watermark compatible with AR. AR is an inference-time mitigation technique that samples multiple watermarked completions for a given prompt and selects the best according to an external reward model. We also tried picking the best sample by perplexity instead of reward. This still hurt alignment. So perplexity and alignment degradation are independent –– you can’t use perplexity to predict alignment damage.
Two to four samples per query is enough. This recovers –– and often surpases, the alignment of unwatermarked models.
Broader Implications
We need reliable watermarking to authenticate AI outputs. But if we’re not careful, watermarking will undermine alignment. The good news? The trade-off between watermark strength and alignment is manageable. You can fix it at inference time.
Citation
If you found this work helpful, please consider citing our paper:
@inproceedings{vermawatermarking,
title={Watermarking Degrades Alignment in Language Models: Analysis and Mitigation},
author={Verma, Apurv and Phan, Hai and Trivedi, Shubhendu},
booktitle={The 1st Workshop on GenAI Watermarking}
}