Watermarking Degrades Alignment in Language Models ![]()
Analysis and Mitigation
Apurv Verma, NhatHai Phan, Shubhendu Trivedi
tldr;

LLaMA-8B-Inst with KGW watermark (δ=2, γ=0.25)
Truthfulness Assessment
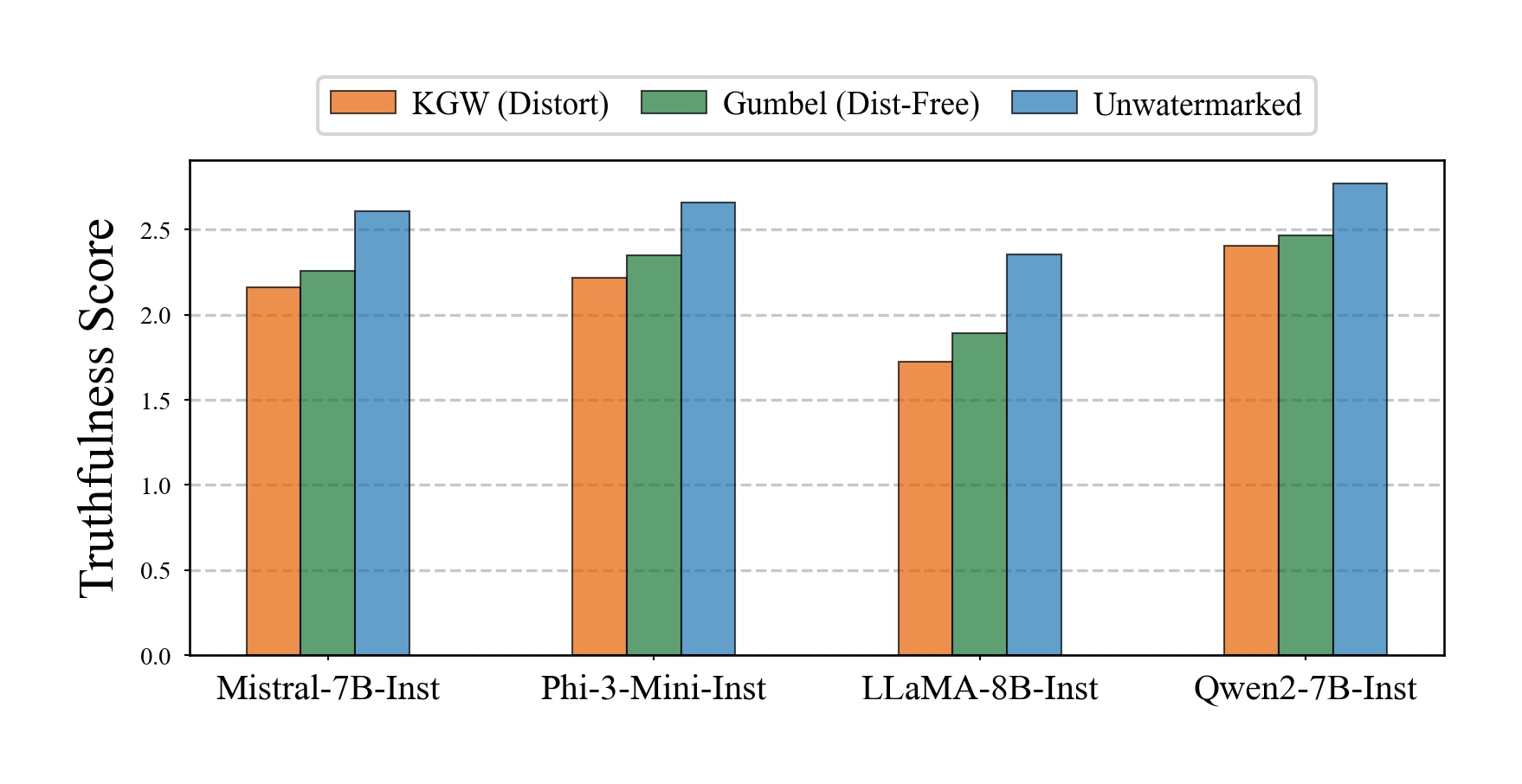
Watermarking reduces truthfulness; KGW (orange) causes larger drops than Gumbel (green).
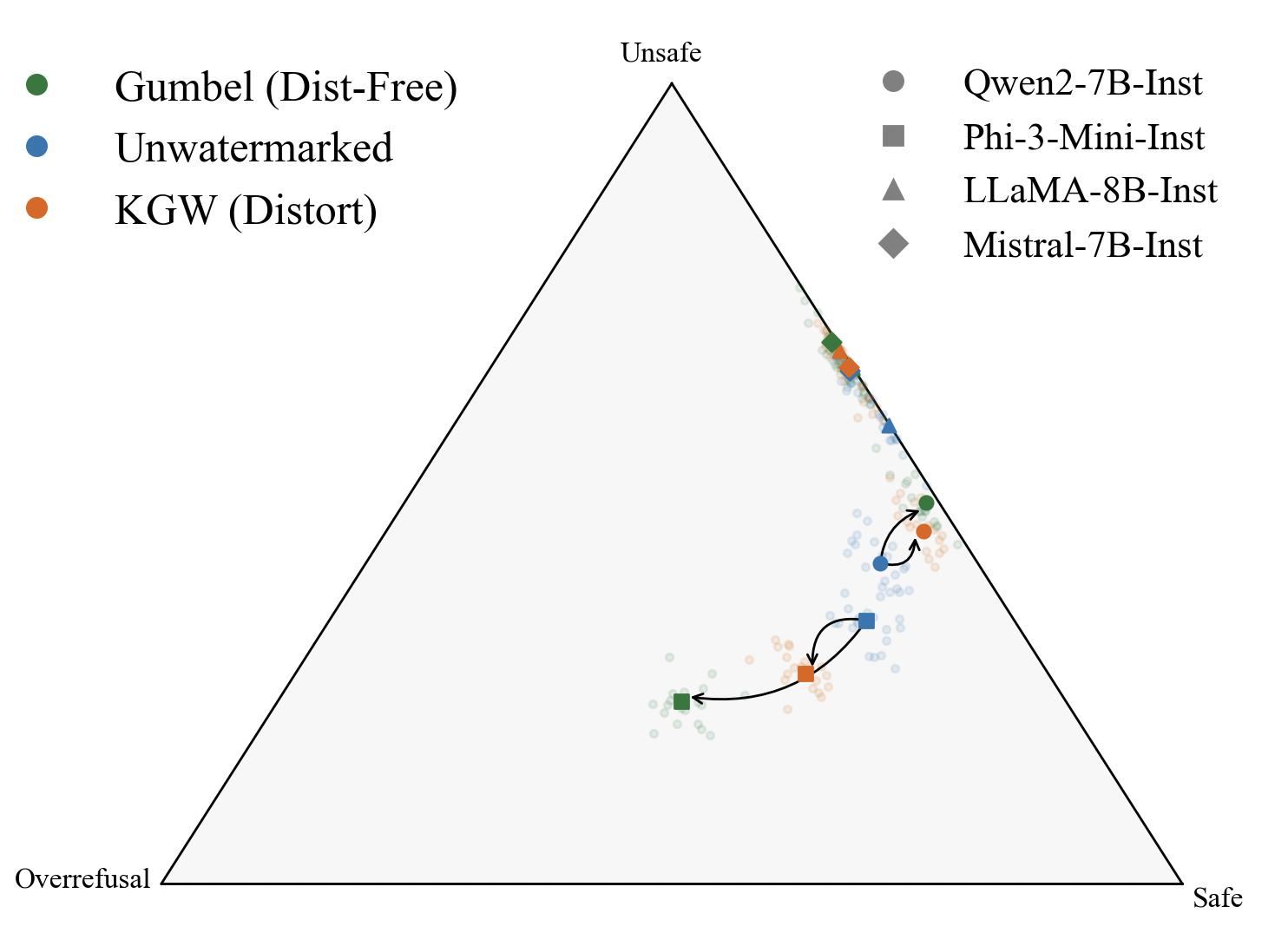
Safety Assessment
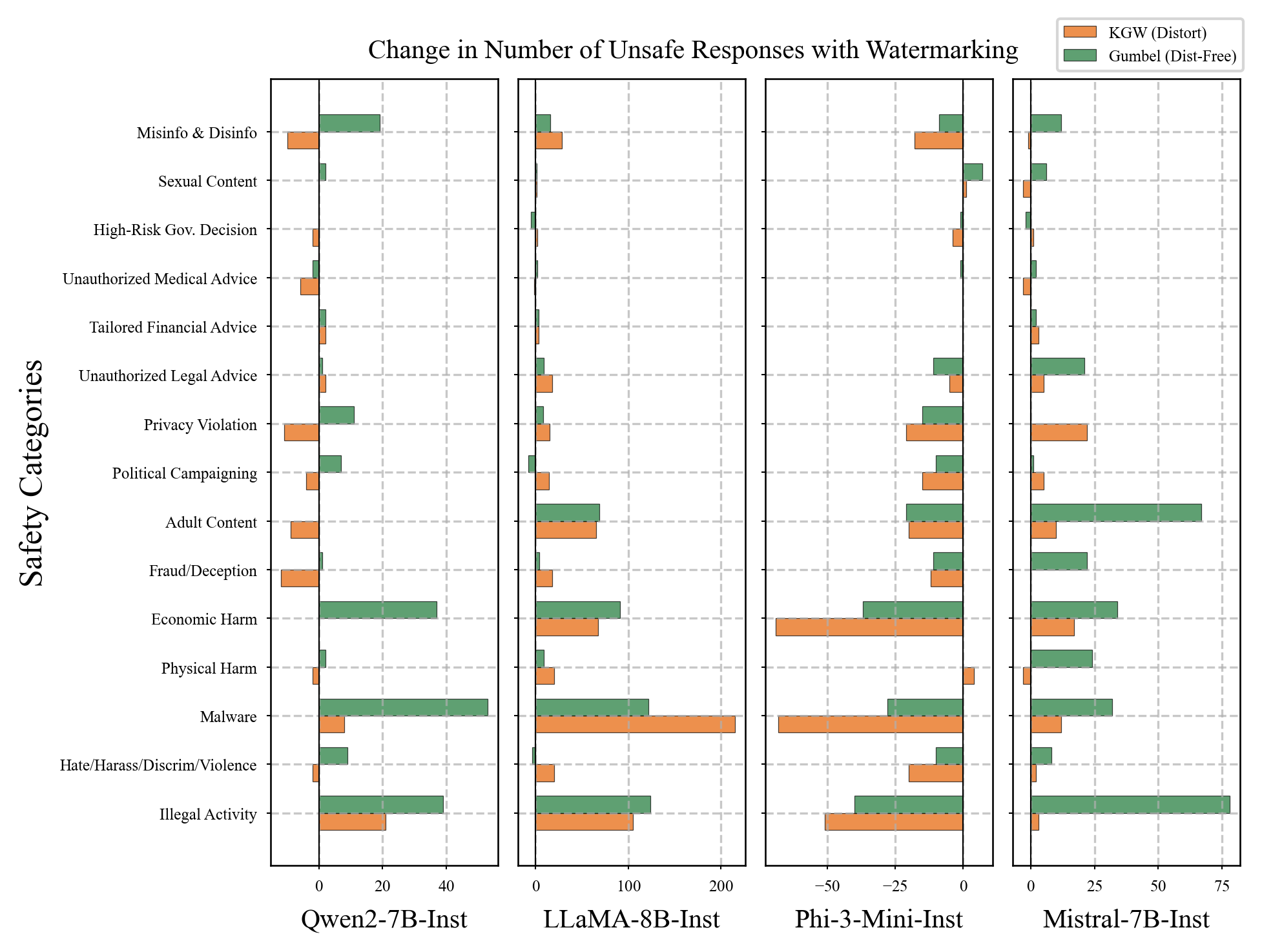
Overrefusal Assessment
Phi-3-Mini: safer but more overrefusals (Guard Amplification) — Qwen: more helpful but less safe (Guard Attenuation)
The Curse of Watermarking
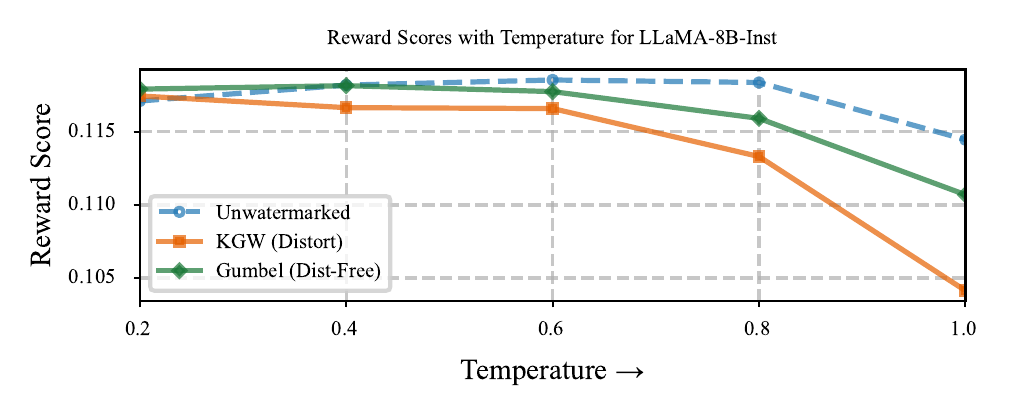
Stronger watermark (higher τ) → better detectability but worse alignment. Even distortion-free Gumbel degrades.
Empirical Validation
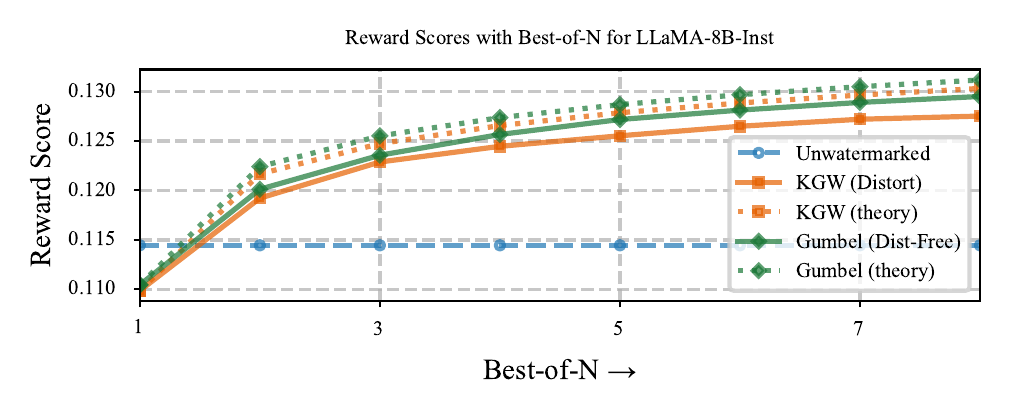
• Theory matches empirical
• √log(n) trend confirmed
n=4 matches baseline
Truthfulness Recovery
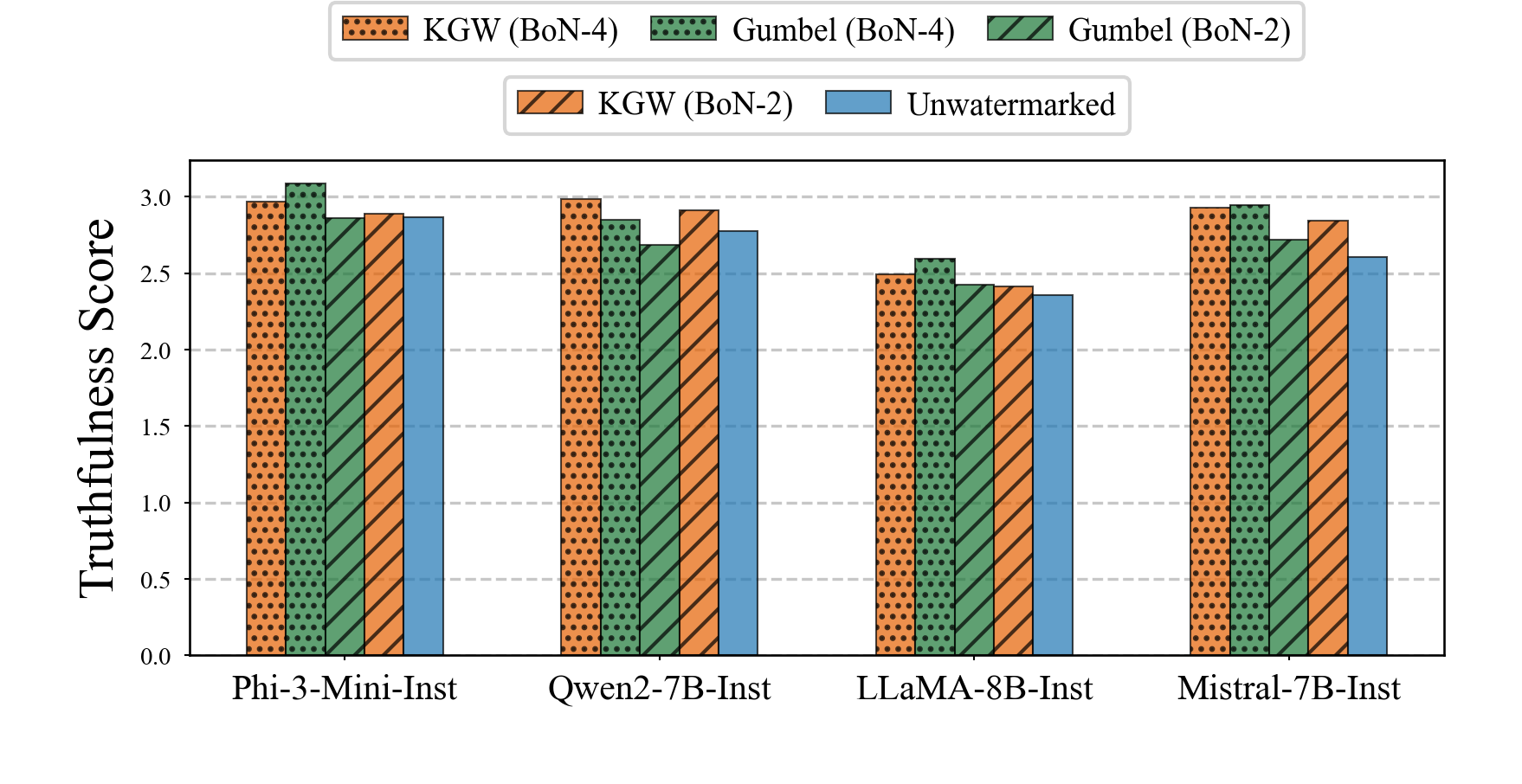
Best-of-N (n=4) recovers truthfulness to match or exceed unwatermarked baseline across all models.
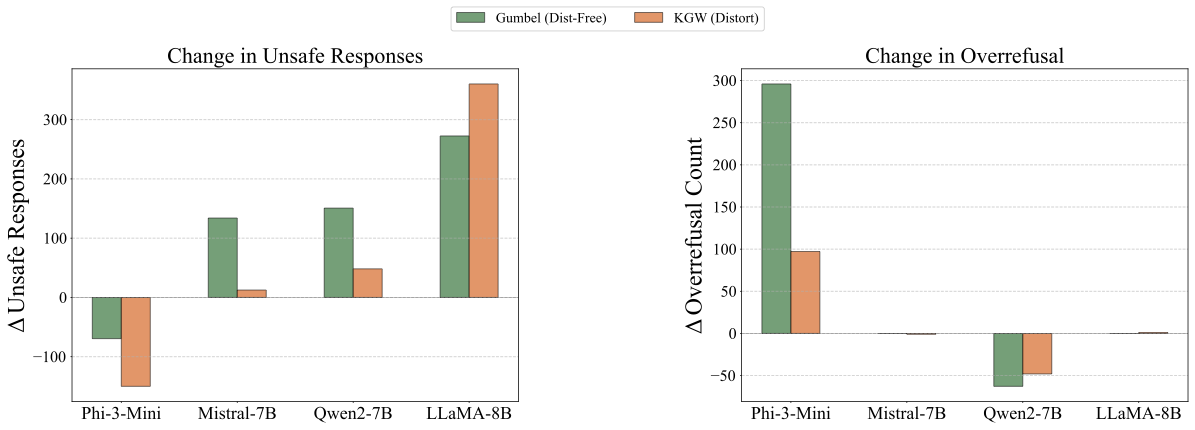
Safety Recovery
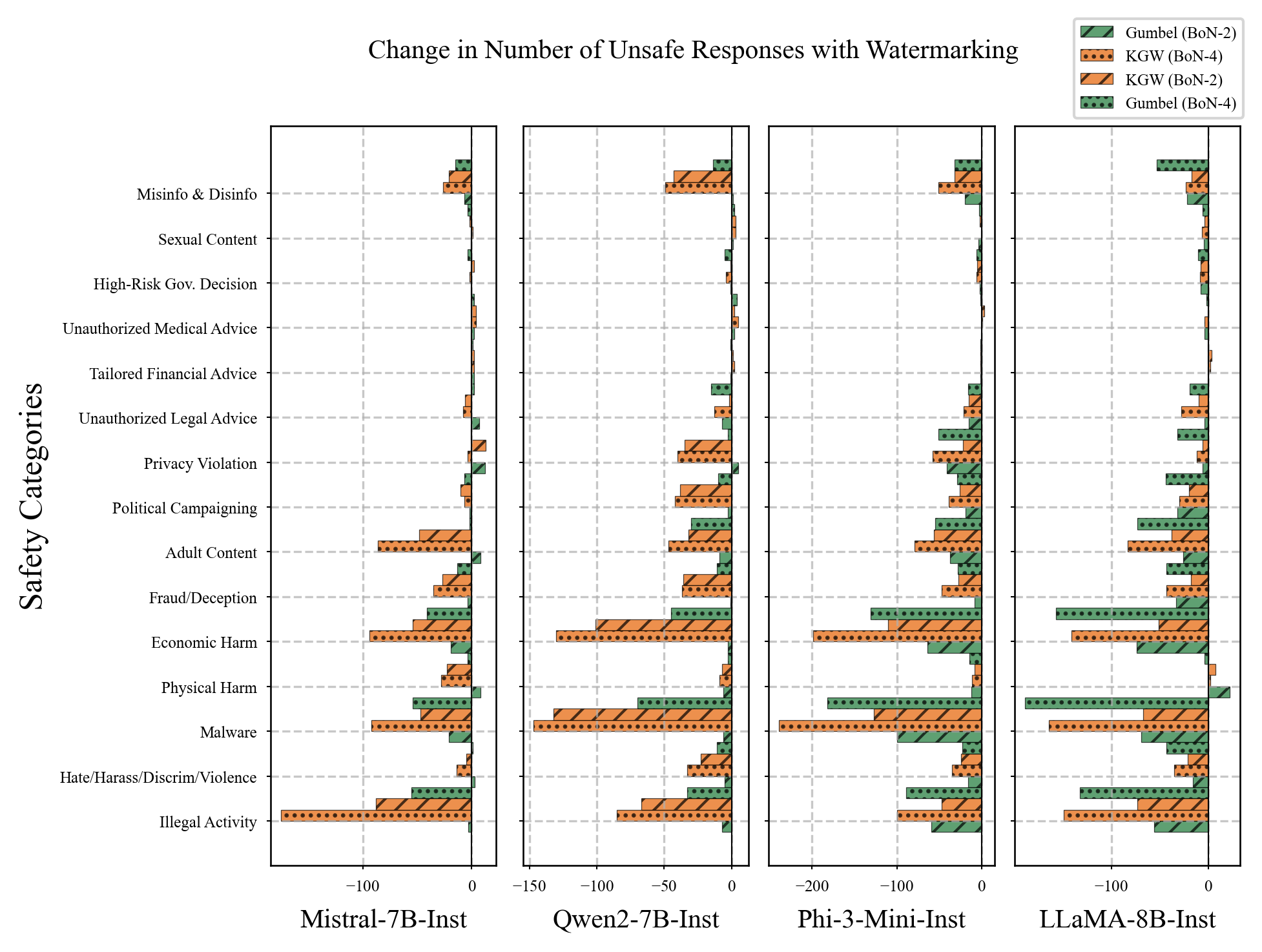
Before & After: Behavioral Recovery
Before (Watermarked)
After (Best-of-N)
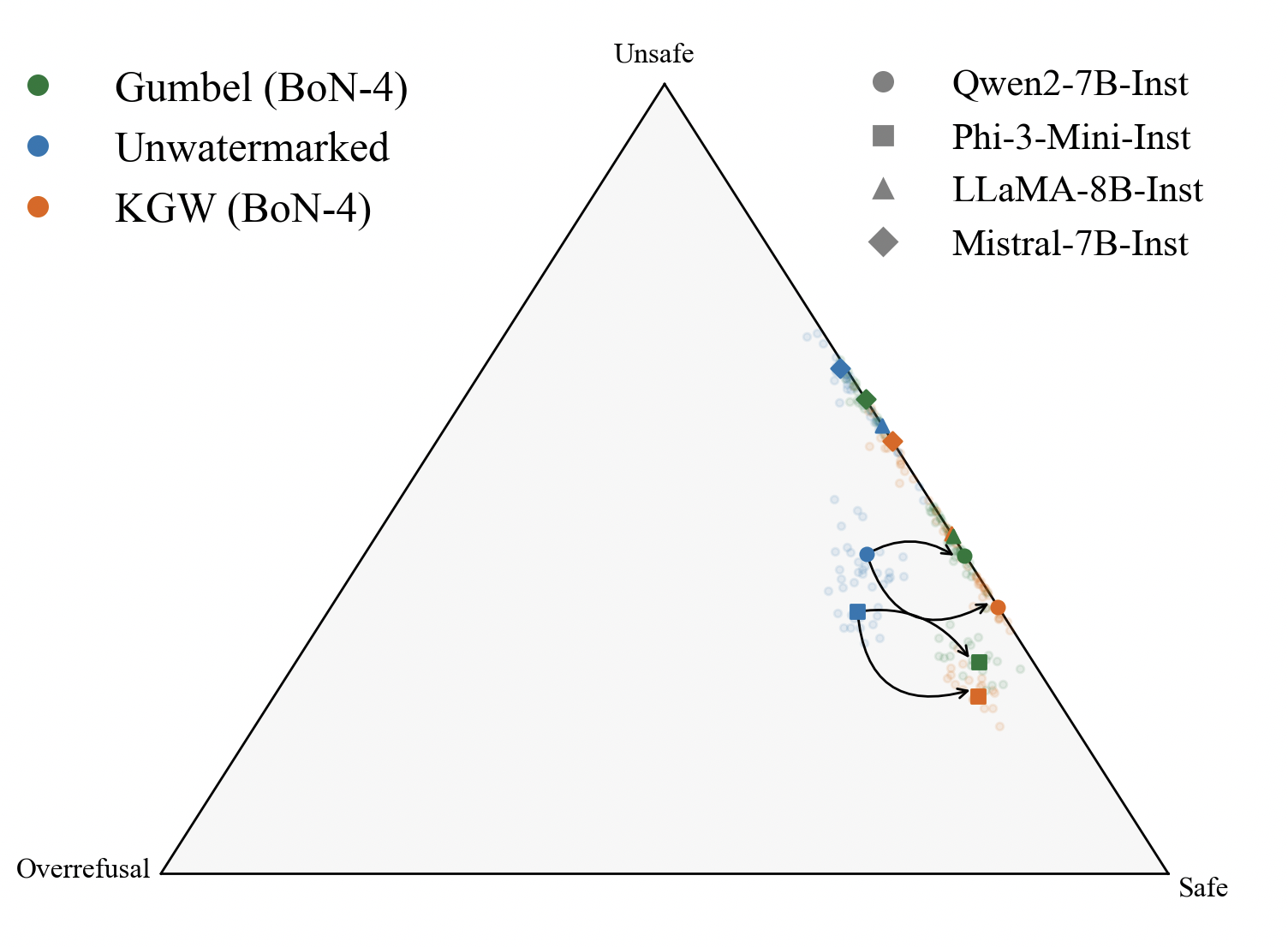
Best-of-N restores models toward optimal balance — reducing both unsafe responses and overrefusals.
Thank You

Contribute your watermarking algorithm to the library!
Appendix: Scaling Analysis
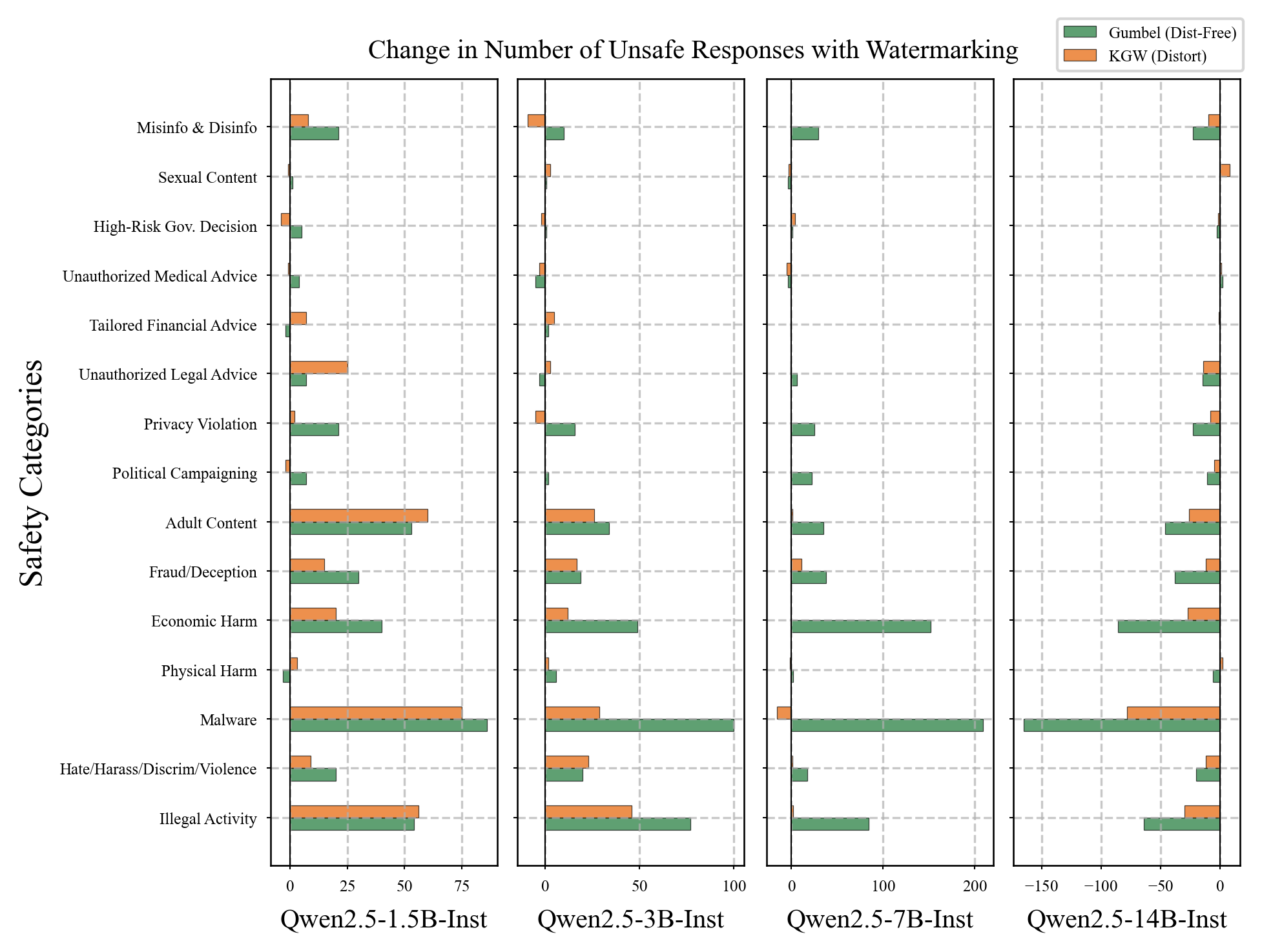
Safety degradation across Qwen2.5 family (1.5B–14B)
Key findings:
- Larger models: more robust to KGW
- Larger models: more vulnerable to Gumbel
Truthfulness:
- Consistently degrades across all scales
- KGW effect stronger than Gumbel
⚠️ Model scale provides no universal protection against watermark-induced alignment degradation
Appendix: Modified Gumbel for Diversity
Standard Gumbel

Deterministic: argmax selection
Modified Gumbel

Stochastic: multinomial sampling
The trade-off: Sacrifice theoretical distortion-freeness for practical diversity
- Standard Gumbel: \(P(x^* = i) = p_i\) exactly, but identical outputs per prompt
- Modified Gumbel: \(\mathbb{E}_G[q_i(G)] \neq p_i\), but enables Best-of-N selection