Imagine asking ChatGPT for homework help and receiving the response “Please die.” Or picture discovering that an AI chatbot has leaked someone’s private medical information. These are real incidents that have made headlines in recent months.
As Large Language Models (LLMs) become deeply integrated in various professions – from helping doctors diagnose patients to assisting lawyers with case research – their safety and security has never been more critical. While these AI systems show remarkable capabilities, they can also exhibit concerning behaviors like generating harmful content, leaking private information, or being manipulated to bypass their built-in safety measures.
The AI research community has been actively studying these vulnerabilities, but until now, most work has focused on specific types of attacks or defenses in isolation. What’s been missing is a comprehensive framework for understanding the full landscape of threats – from how attackers might compromise these systems to how we can defend against such attempts.
Our new paper, “Operationalizing a Threat Model for Red-Teaming Large Language Models,” aims to fill this gap. We present the first systematic analysis of LLM security, mapping out the various ways these systems can be attacked, identifying their vulnerable points, and outlining strategies for testing and protecting them. Think of it as a complete security guide for the age of AI – one that’s essential for anyone building, deploying, or interested in the safety of LLM applications.
Attack Taxonomy
While prior literature has attempted to systematize attacks on Large Language Models (LLMs), these taxonomies have largely centered around loosely defined terms like ‘jailbreaks’ and ‘prompt injection’ – nomenclature that, while widespread, lacks theoretical rigor and offers limited practical insight to ML practitioners. Our research introduces a novel way to categorize these attacks based on a fundamental principle that underlies all security vulnerabilities: the level of access required to execute them.
This access-based taxonomy, illustrated in Figure 1, presents a hierarchical organization of attacks ranging from those requiring minimal access (such as crafting malicious prompts) to those demanding privileged access to the model’s training pipeline. This systematic categorization not only provides ML practitioners with an intuitive framework for threat assessment but also facilitates the implementation of targeted defensive measures at each access level.
 Figure 1: Taxonomy of attacks on LLMs
Figure 1: Taxonomy of attacks on LLMs
Attack Surface Visualization
Having introduced our taxonomy of attacks, we present a visual representation in Figure 2 in what we term as “attack surface visualization”. Reading from left to right, the figure traces the full lifecycle of an LLM system. On the left, we see attack vectors targeting the “finished product” – the user-facing application where people input their prompts and receive responses. As we move right, we encounter progressively deeper levels of the system, ultimately reaching its foundations: the training data and algorithms that give the LLM its capabilities. The figure employs a systematic visual encoding scheme:
Colored boxes mark different types of attack vectors, each corresponding to a category from our taxonomy Black arrows show how information normally flows through the system Gray arrows reveal “side channels” – subtle vulnerabilities that emerge from standard practices like data deduplication (where duplicate data is removed to improve efficiency)
This visualization serves a crucial purpose: it helps security teams and developers think like attackers. By understanding all possible entry points – from the most obvious (like malicious prompts) to the most subtle (like exploiting data preprocessing) – we can better protect LLM systems at every stage of their lifecycle. This comprehensive view of attack surfaces and entry points leads us to several crucial questions that security teams and developers must address when building and deploying LLM systems.
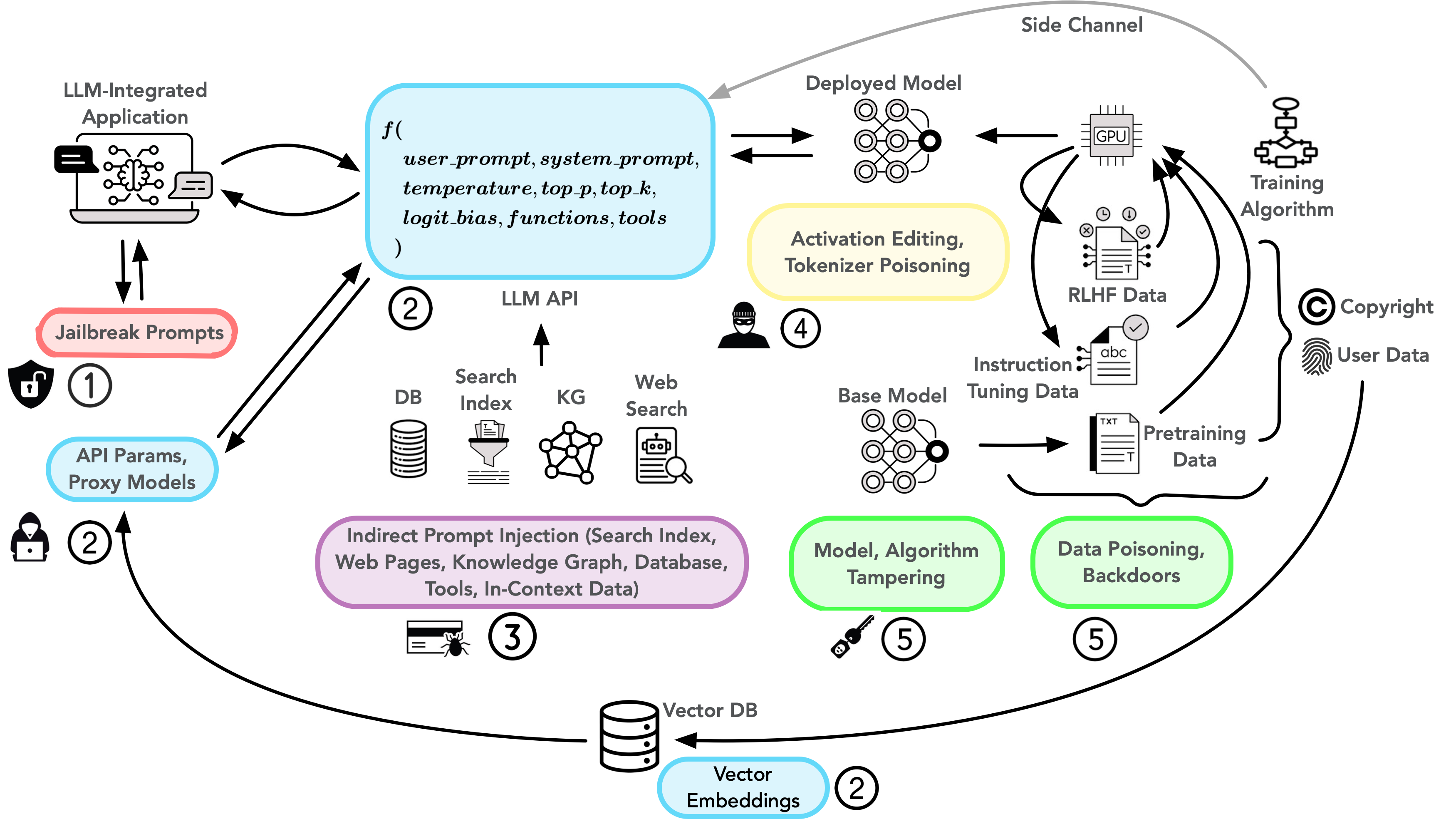 Figure 2: Visualization of attack vectors and their corresponding entry points
Figure 2: Visualization of attack vectors and their corresponding entry points
Key Questions Addressed
The comprehensive attack surface visualization above not only reveals the complexity of LLM security but also frames the fundamental questions that our research addresses. Through a detailed survey of existing literature and industry practices, our paper tackles the following key security challenges and questions:
- How does red-teaming evaluation differ from traditional benchmarking in uncovering vulnerabilities
- Who are the potential adversaries and what capabilities they possess at each entry point
- Clear definitions of often-confused terms like Direct vs. Indirect Prompt Injection
- Practical strategies for detecting and mitigating backdoor triggers
- A systematic categorization of defense strategies aligned with different attack vectors
- Deep dives into subtle vulnerabilities like side-channel attacks
- Evidence-based best practices and limitations of red-teaming exercises
Staying Current
LLM security is a rapidly moving target, with new attack vectors and defense strategies emerging regularly. To help researchers and practitioners stay updated, we maintain a GitHub repository tracking papers in the area. While recent work on red-teaming has predominantly focused on prompt-based attacks, effective red-teaming must encompass the entire model development pipeline. As LLMs become increasingly integrated into critical systems, the community must broaden its security focus to address vulnerabilities across all levels of access identified in our taxonomy.
Citation
If you found this work helpful for understanding and securing LLM systems, please consider citing our paper:
@article{verma2024operationalizing,
title={Operationalizing a Threat Model for Red-Teaming Large Language Models (LLMs)},
author={Verma, Apurv and Krishna, Satyapriya and Gehrmann, Sebastian and Seshadri, Madhavan and Pradhan, Anu and Ault, Tom and Barrett, Leslie and Rabinowitz, David and Doucette, John and Phan, NhatHai},
journal={arXiv preprint arXiv:2407.14937},
year={2024}
}