Red-teaming has emerged as a critical technique for identifying vulnerabilities in real-world LLM implementations. In our latest paper we present a detailed threat model and provide a systematization of knowledge (SoK) of red-teaming attacks on LLMs. We create a taxonomy of attacks based on the entry points in the phases of an LLM development and deployment lifecycle. This method of structuring is more familiar to an ML practitioner.
Based on the threat-model we operationalize the attacks in increasing order of level of access required. The following figure illustrates the attack vectors corresponding to the various attacks in our proposed taxonomy. Attacks on the left side target late entry points in the lifecycle stage, such as application input, whereas attacks on the right side target early entry points such as training data, algorithm, etc. The colored boxes indicate the attack vectors corresponding to each high-level attack type in our taxonomy. Black arrows indicate the flow of information or artifacts, while gray arrows indicate side channels exposed due to the knowledge of common data-preprocessing steps such as data deduplication, etc.
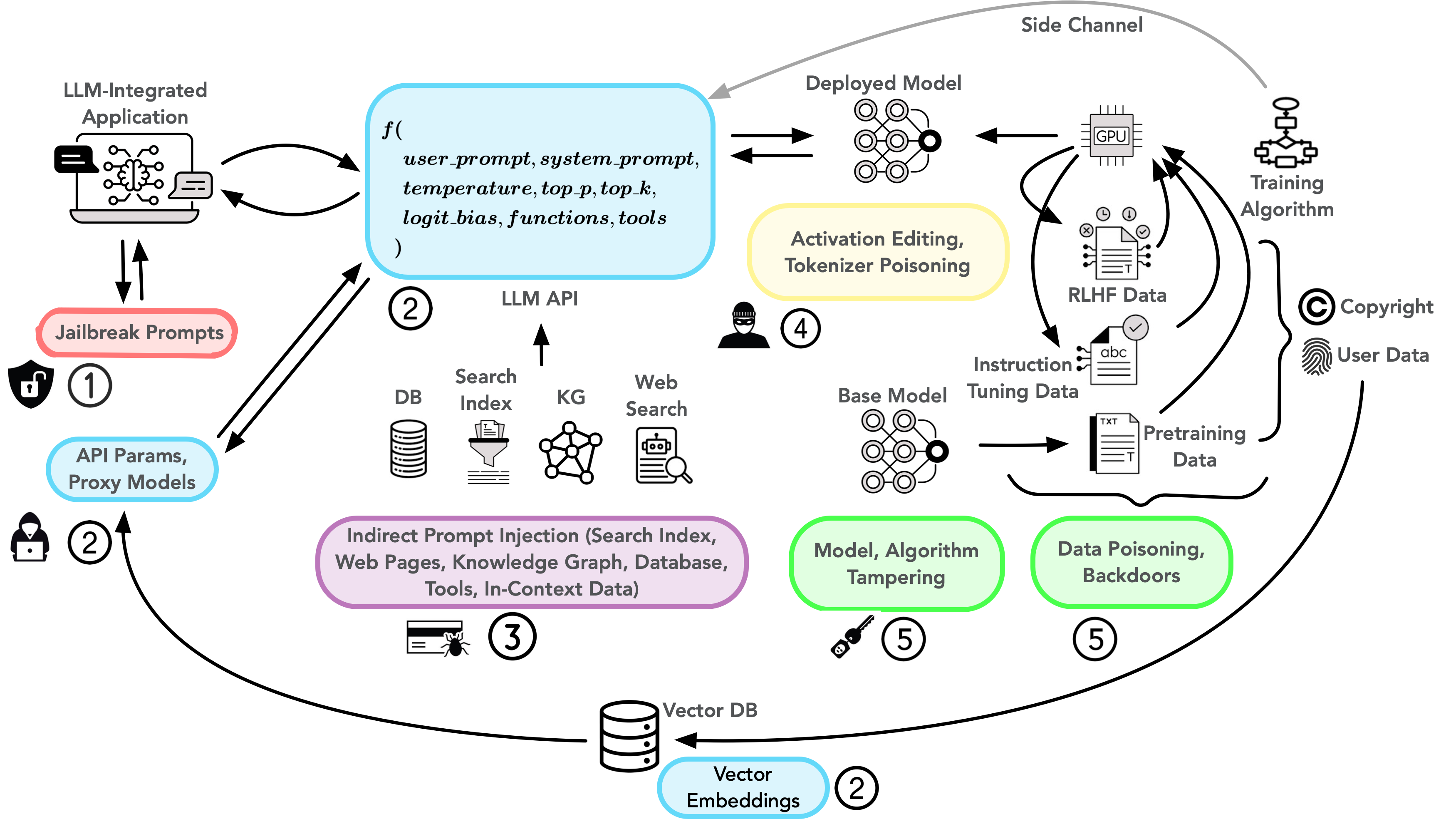
Finally we describe various defense methodologies, approaches for effective red-teaming and discuss challenges and future directions. The paper systematizes insights from previous papers and helps answer some of the following questions
- What is the difference between red-teaming evaluation and traditional benchmarking evaluation ?
- Who are the potential adversaries and bad actors and what are their goals and capabilities ?
- What do terms such as Direct Prompt Injection, Indirect Prompt Injection, Jailbreak, and Side-Channels, among others, mean ?
- What are the strategies to detect and recover backdoor triggers ?
- What are the broad categories of defense strategies employed ?
- What are side-channel attacks? How do architecture and data processing choices introduce vulnerabilities ?
- What are the recommendations when conducting a red-teaming exercise and its inherent limitations ?
To facilitate easy updates to our taxonomy, we release a repo with a list of all the papers in our attack taxonomy. We also provide takeaways for practitioners for effective red-teaming and defense.
BibTex
@article{verma2024operationalizing,
title={Operationalizing a Threat Model for Red-Teaming Large Language Models (LLMs)},
author={Verma, Apurv and Krishna, Satyapriya and Gehrmann, Sebastian and Seshadri, Madhavan and Pradhan, Anu and Ault, Tom and Barrett, Leslie and Rabinowitz, David and Doucette, John and Phan, NhatHai},
journal={arXiv preprint arXiv:2407.14937},
year={2024}
}